Adapting a Foundation Model for Space-based Tasks
Matthew Foutter, Praneet Bhoj, Rohan Sinha, Amine Elhafsi, Somrita Banerjee, Christopher Agia, Justin Kruger, Tommaso Guffanti, Daniele Gammelli, Simone D’Amico, and 1 more author
In RSS’24 Workshop on Semantics for Robotics: From Environment Understanding and Reasoning to Safe Interaction, 2024
Foundation models, e.g., large language models, possess attributes of intelligence which offer promise to endow a robot with the contextual understanding necessary to navigate complex, unstructured tasks in the wild. In the future of space robotics, we see three core challenges which motivate the use of a foundation model adapted to space-based applications: 1) Scalability of ground-in-the-loop operations; 2) Generalizing prior knowledge to novel environments; and 3) Multi-modality in tasks and sensor data. Therefore, as a first-step towards building a foundation model for space-based applications, we automatically label the AI4Mars dataset to curate a language annotated dataset of visual-question-answer tuples. We fine-tune a pretrained LLaVA checkpoint on this dataset to endow a vision-language model with the ability to perform spatial reasoning and navigation on Mars’ surface. In this work, we demonstrate that 1) existing vision-language models are deficient visual reasoners in space-based applications, and 2) fine-tuning a vision-language model on extraterrestrial data significantly improves the quality of responses even with a limited training dataset of only a few thousand samples.







 Semantic Anomaly Detection with Large Language ModelsIn Robotics, Systems and Science; Workshop Towards Safe Autonomy: New Challenges and Trends in Robot Perception, 2023
Semantic Anomaly Detection with Large Language ModelsIn Robotics, Systems and Science; Workshop Towards Safe Autonomy: New Challenges and Trends in Robot Perception, 2023







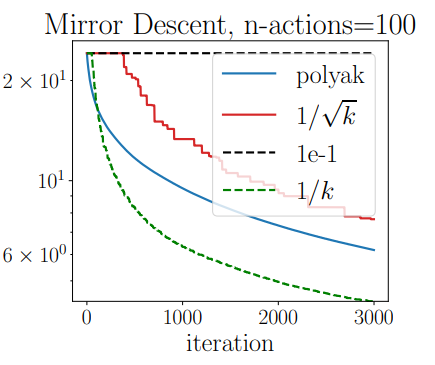
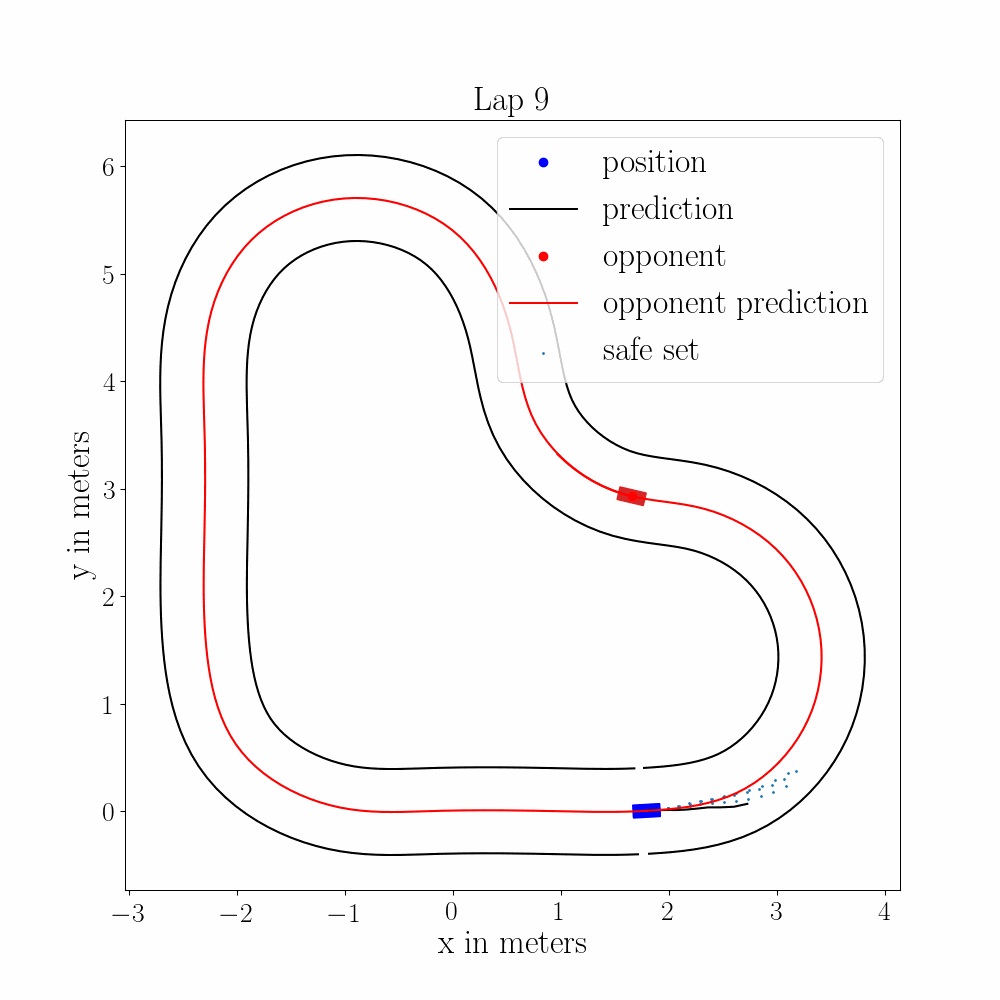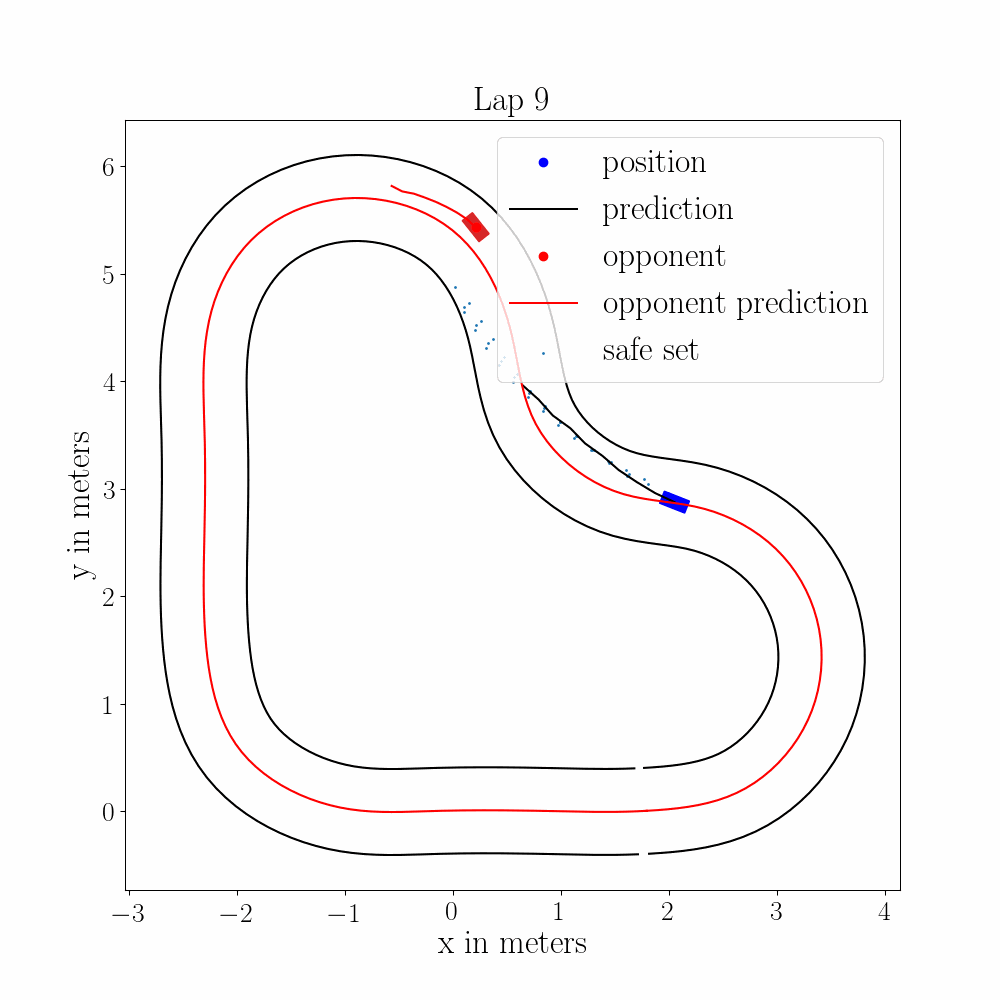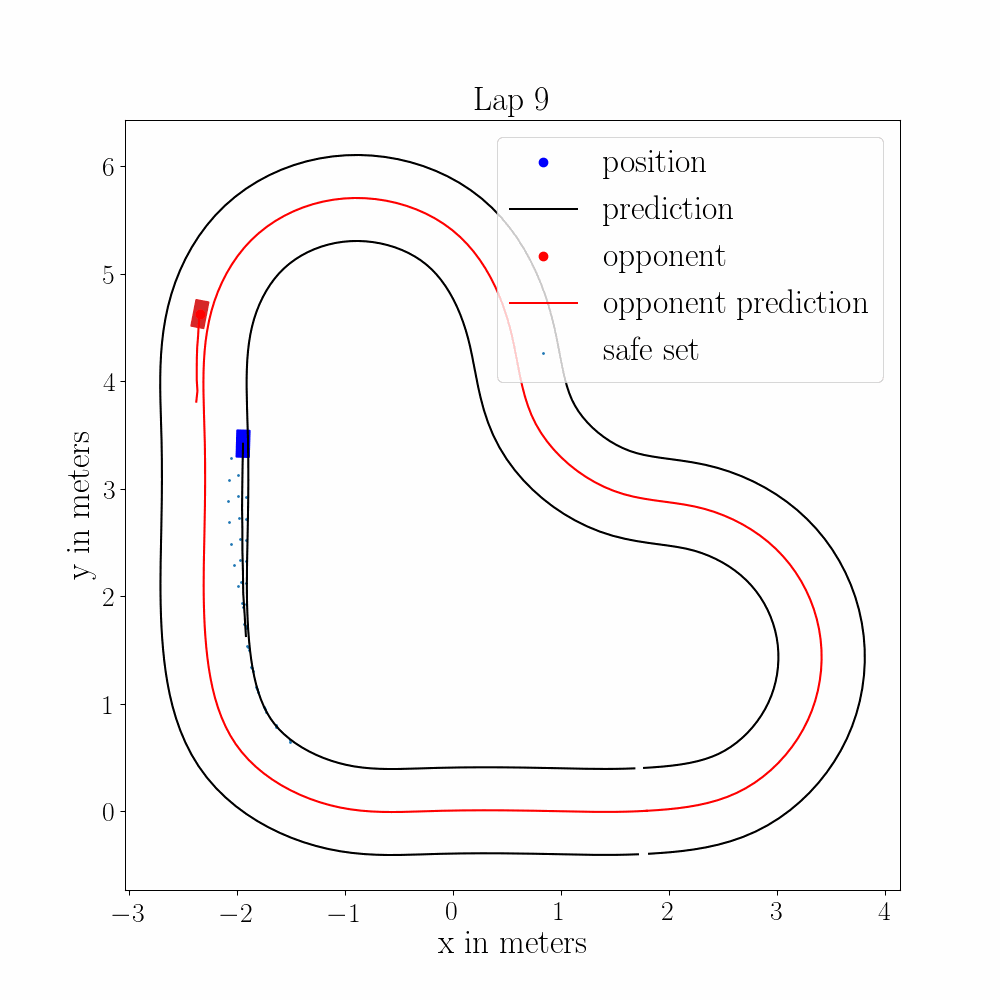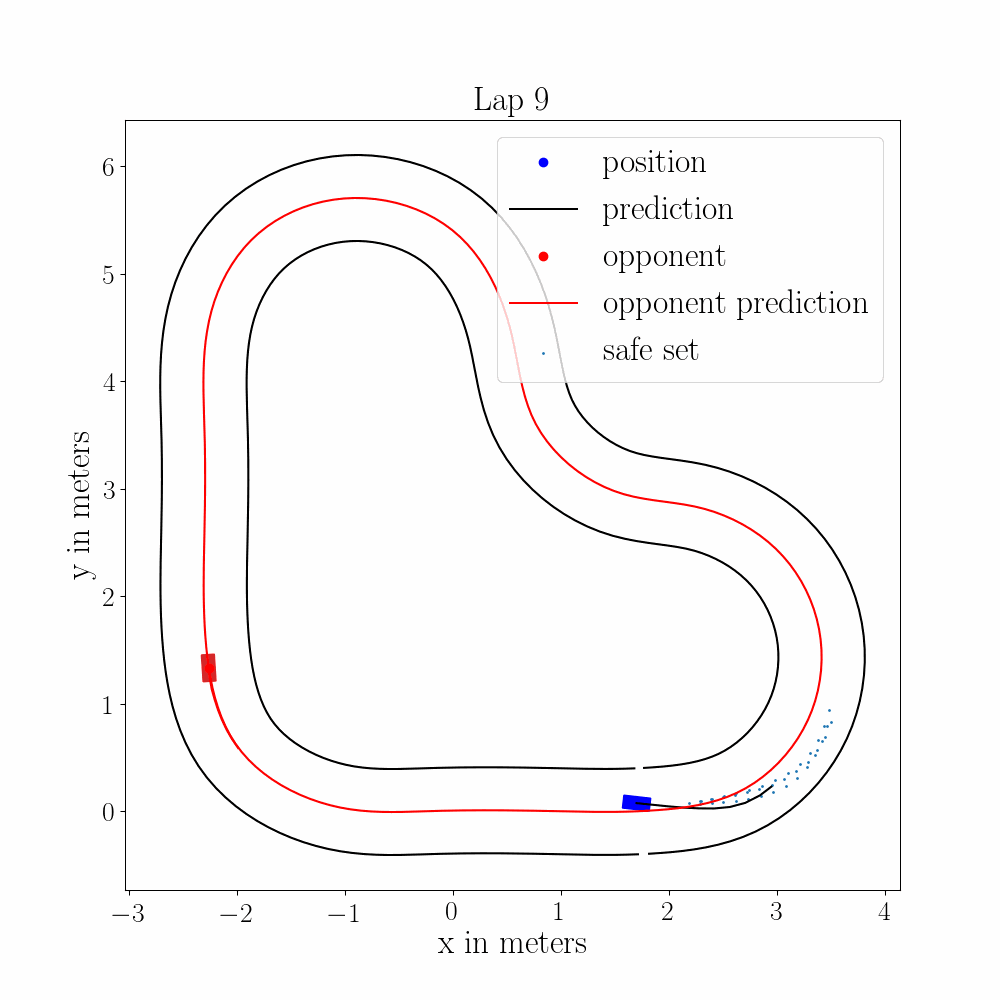 Multi-Vehicle Autonomous Racing with Learning MPC and Trajectory ForecastingTech. Report for AA277, 2021
Multi-Vehicle Autonomous Racing with Learning MPC and Trajectory ForecastingTech. Report for AA277, 2021


 MPC Control of Multiple Quadcopters Cooperatively Lifting an ObjectTech. Report for UC Berkeley ME231A, 2019
MPC Control of Multiple Quadcopters Cooperatively Lifting an ObjectTech. Report for UC Berkeley ME231A, 2019

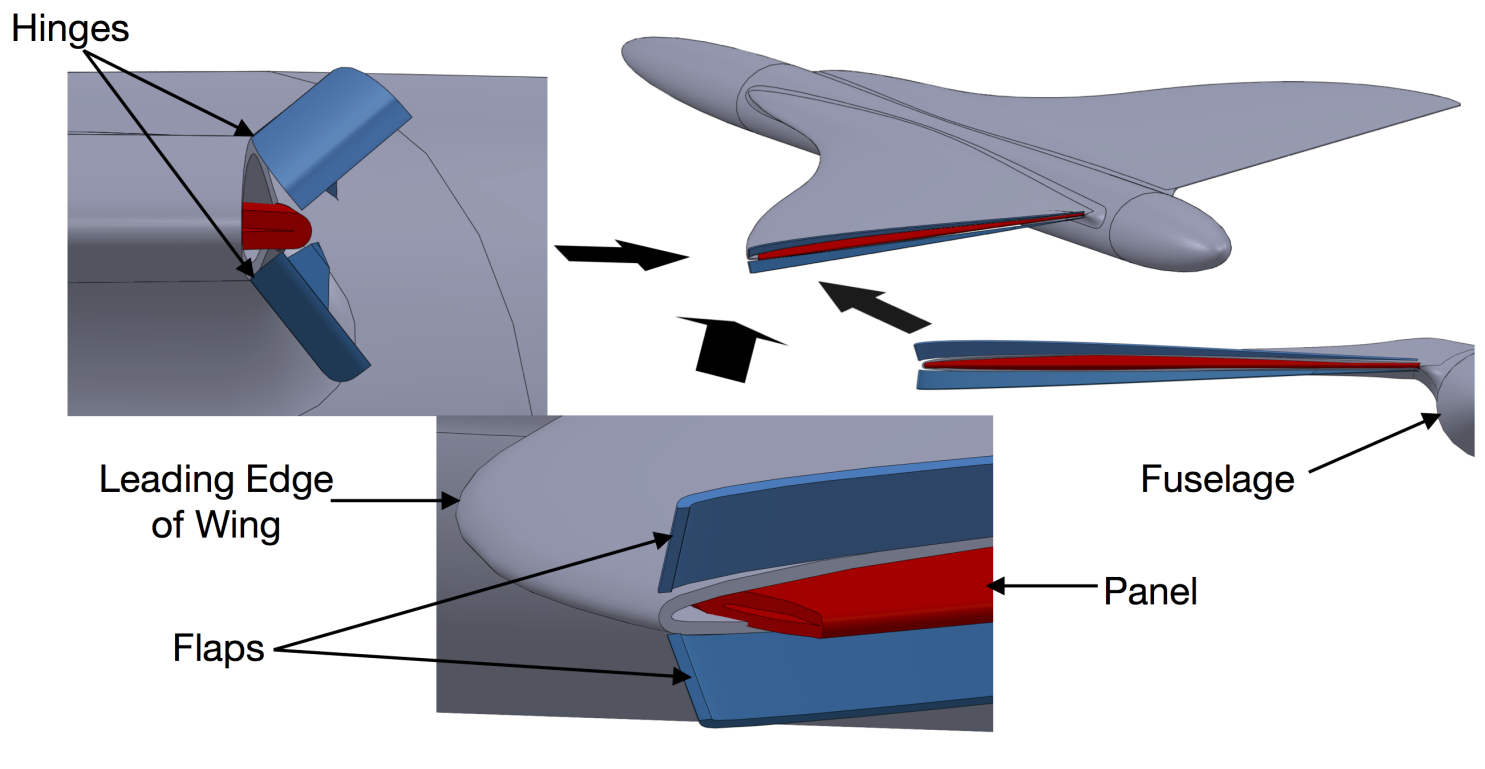 Goldeneye AB1In Presented at NASA Aeronautics Design Challenge, 2017(Third place/honorable mention)
Goldeneye AB1In Presented at NASA Aeronautics Design Challenge, 2017(Third place/honorable mention)